NIM : 112100925
Nama : Joko Gunawan
Semester/Kelas : 5/C3
Jurusan : Teknik Informatika
Jenjang : S1
Matakuliah : Perancangan Sistem Informasi
Soal:
List the eight general guidelines for proper coding.
List six data entry methods.
Soal:
Daftar delapan panduan umum untuk persiapan kode.
Daftar enam metode masukan data.
Jawaban nomor 1:
panduan umum untuk persiapan kode:
Meringkas
Kode seharusnya diringkas. Kode yang terlalu panjang berarti banyak tombol dan akibatnya banyak kesalahan. Kode panjang juga berarti bahwa penyimpanan informasi dalam basis data akan memerlukan banyak memori.
Kode singkat lebih mudah untuk diingat dan lebih mudah untuk dimasukkan daripada kode panjang. Jika kode harus panjang, seharusnya dipecah ke dalam subkode. Untuk contoh, 5678923453127 dapat dipecah dengan tanda penghubung sebagai berikut: 5678-923-453-127. Pendekatan ini lebih mudah diatur dan memberikan keuntungan cara orang mengetahui proses informasi dalam potongan singkat. Terkadang kode dibuat lebih panjang untuk mencegah orang dari menduga suatu nomor kartu kredit. Visa dan MasterCard menggunakan nomor 16 digit, akan menampung sembilan triliun pelanggan. Karena nomor-nomor tidak ditandai secara berderet, kesempatan untuk menebak nomor kartu kredit sangat kecil.
Menjaga kode tidak berubah
Kestabilan berarti bahwa identifikasi kode untuk pelanggan seharusnya tidak berubah setiap kali data diterima. Saat ini, kita mencontohkan suatu kode derivasi abjad untuk suatu daftar pelanggan majalah. Tanggal waktu terakhir bukan bagian dari kode identifikasi pelanggan karena biasanya mengubah.
Jangan mengubah singkatan kode di dalam sistem Mnemonik. Suatu waktu Anda mempunyai pilihan singkatan kode, jangan mencoba untuk memperbaikinya, karena itu membuatnya sangat sulit bagi masukan data untuk mengadaptasi.
Memastikan bahwa kode adalah unik
Bagi kode supaya bekerja, harus unik perhatikan bahwa semua kode yang digunakan dalam sistem dan memastikan bahwa Anda tidak menggunakan nomor atau nama kode sama untuk item-item yang sama. Nomor dan nama kode merupakan bagian yang sangat penting dari masukan dalam kamus data.
Membiarkan kode dapat diurut
Jika anda akan memanipulasikan data dengan bermanfaat, kode harus dapat diurut. Untuk contoh, jika Anda menjalankan teks cari pada bulan-bulan dalam setahun di dalam pesanan yang meningkat, "J" bulan akan keluar dari pesanan (Januari, Juli, dan selanjutnya Juni). Kamus dipilih dalam cara ini, satu huruf pada suatu waktu dari kanan ke kiri. Sehingga, jika Anda memilah MMMDDYYYY di mana menempatkan MM untuk singkatan bulan, DD untuk hari, dan YYYY untuk tahun, hasilnya akan salah.
Menghindari kode yang buat kekacauan
Mencoba untuk menghindari penggunaan karakteristik kode yang terlihat atau terdengar serupa. Karakter O (huruf oh) dan 0 (angka nol) sering kacau, seperti huruf I dan angka 1 dan huruf Z dan angka 2. Oleh karena itu, kode seperti B1C dan 280Z adalah tidak memuaskan.
Menjaga kode yang seragam
Kode perlu untuk mengikuti bentuk banyak format sepanjang waktu. Kode yang digunakan bersama, seperti BUF-234 dan KU-3456, adalah kurang baik karena yang pertama terdiri dari tiga huruf dan tiga angka, sedangkan yang kedua hanya mempunyai dua huruf diikuti oleh empat angka.
Pada saat Anda memerlukan tambahan tanggal, cobalah untuk menghindari penggunaan kode MMDDYYYY dalam satu aplikasi, kedua YYYYDDMM, dan ketiga MMDDYYYY. Ini sangat penting untuk menjaga kode seragam untuk semua program.
Sebelumnya, keseragaman berarti bahwa semua kode dijaga sama panjangnya. Dengan permulaan sistem online, panjang tidak sepentingnya dulu. Dengan sistem online, kunci enter dikenai setelah masukan data diuji oleh operator dengan benar, sehingga ini tidak terlalu masalah jika kode panjangnya tiga karakter atau empat karakter.
Membolehkan modifikasi kode
Pencocokan adalah suatu kunci utama dari kode yang baik. Para penganalisis harus mempertimbangkan bahwa sistem akan berkembang dengan waktu, dan sistem pengkodean seharusnya mampu mencakup perubahan. Jumlah pelanggan seharusnya bertambah, pelanggan akan mengganti nama, dan suplier akan memodifikasi cara mereka menamakan produknya. Seorang penganalisis perlu untuk bisa meramalkan perkiraan dan antisipasi menjangkau jauh kebutuhan masa depan saat merancang kode.
Membuat kode berarti
Kalau penganalisis ingin menyembunyikan informasi, kode tetap berarti. Kode yang efektif tidak hanya berisi informasi, tetapi juga membuat pengertian kepada masyarakat penggunanya. Kode yang berarti lebih mudah dimengerti, bekerja dengannya, dan dipanggil. Pekerjaan masukan data menjadi lebih menarik saat bekerja dengan kode yang berarti daripada hanya memasukkan rangkaian angka-angka kurang berarti.
Menggunakan kode
Kode-kode bisa digunakan dengan banyak cara. Di dalam validasi program, masukan data diperiksa pada datar kode untuk memastikan bahwa hanya kode valid yang dimasukkan. Di dalam program laporan dan penyelidikan, kode disimpan pada file yang ditransform ke dalam pemahaman kode. Laporan dan layar seharusnya tidak menampilkan atau mencetak kode sebenarnya. Jika mereka melakukan, pemakai akan mempunyai ingatan kode yang berarti atau melihat mereka secara manual. Kode digunakan dalam program GUI untuk menghasilkan daftar drop-down.
Jawaban nomor 2:
Enam metode masukan data:
Papan ketik
Papan ketik merupakan metode paling tua masukan data, dan tentunya adalah alat yang sangat akrab dengan anggota organisasi. Beberapa perbaikan telah dibuat beberapa tahun terakhir ini untuk standarisasi papan ketik, seperti menambah numerik keypad yang dapat diprogram dengan macros untuk mengurangi jumlah keystroke yang diperlukan dan penemuan yang baik (satu dibentuk untuk bentuk tangan). Perangkat lunak mengizinkan pencarian kembali untuk menganalisis berapa banyak keystroke yang diperlukan untuk memasukkan jenis data tertentu.
Optical Character Recognition
Optical Character Recognition membiarkan pengguna membaca masukan dari dokumen sumber dengan optical scanner lebih baik daripada media magnetik. Penggunaan alat OCR dapat mempercepat masukan data dari 50 hingga 75 persen dari beberapa metode dasar lainnya.
Metode masukan data lainnya
Metode masukan data lainnya secara luas juga mulai banyak dipakai. Sebagian besar metode ini mengurangi biaya kerja dengan memerlukan sedikit keterampilan operator atau pelatihan singkat, mereka menjadikan masukan data mirip dengan sumber data, dan mereka mengeleminasi keperluan akan dokumen sumber. Sama halnya, mereka menjadi metode masukan data yang cepat dan sangat dapat dipercaya. Metode-metode masukan data dibicarakan dalam bagian berikut meliputi pengenalan karakter tinta magnetik, formulir Mark-sense, punch-out formulir, bar code, dan data strip.
Pengenalan karakter tinta magnetik.
Karakter tinta magnetik dijumpai dibawah cek bank dan beberapa tagihan kartu kredit. Metode ini smaa dengan OCR dalam membaca karakter khusus, tetapi penggunaannya terbatas. Masukan data melalui pengenalan karakter tinta magnetik (MICR) dikerjakan melalui mesin yang membaca dan menginterpretasi garis tunggal material yang disandikan dengan tinta yang dibuat dari partikel magnetik.
Beberapa keuntungan menggunakan MICR yaitu (1) MICR metode yang andal dan berkecepatan tinggi yang tidak mudah menerima tanda salah (karena mereka tidak disandikan secara magentik); (2) jika dia digunakan pada pengambilan uang melalui cek, dia menyediakan tingkat keamanan terhadap cek yang tidak beres; (3) personel masukan data dapat melihat nomor kode jika dia perlu memeriksanya.
Formulir mark-sense
Formulir mark-sense membolehkan masukan data melalui penggunaan scanner yang merasakan di mana tanda telah dibuat dengan pencil timah pada formulir khusus. Satu kekurangan dari formulir mark-sense di mana seharusnya pembaca dapat menentukan apakah tanda telah dibuat, tidak dapat mengenali tanda sama yang dikerjakan oleh pembaca karakter optika. Tanda yang tidak jelas pada formulir kemudian dimasukkan sebagai data yang salah. Sebagai tambahan, pilihan terbatas diberikan dalam menyediakan formulir mark-sense. formulir mempunyai kesulitan dalam menangkap data alphanumerik karena diperlukan ruang untuk melengkapi huruf dan angka, dan dia dengan mudah mengisi di luar formulir mark-sense untuk menerima kekeliruan dan menaruh tanda dalam letak yang salah.
Bar kode
Bar kode secara khusus tampak pada label produk, tetapi juga muncul pada gelang identifikasi pasien dalam rumah sakit dan dalam beberapa konteks dimana seseorang atau objek perlu diuji kedalam atau keluar dari beberapa macam sistem inventaris. Bar kode dapat dipikirkan sebagai "metacode" atau kode yang menyandikan kode, karena muncul sebagai seri pita sempit dan lebar pada label yang menyandikan angka atau huruf. Simbol ini mempunyai akses dengan data produk yang disimpan dalam memori komputer. Sorotan cahaya dari scanner atau lightpen menggambar pita yang membentang pada label baik untuk mengkonfirmasi maupun merekam data tentang produk yang lagi di-scan.
Menggunakan terminal cerdas
Terminal cerdas dapat diingat selangkah di atas terminal bodoh dan selangkah di bawah workstation cerdas dan mikrokomputer portabel di dalam kemampuannya. Dalam beberapa hal, terminal cerdas mengeleminasi keperluan akan dokumen sumber.
Keuntungan besar pemakaian terminal cerdas adalah melalui penggunaan pengolah-mikro, mereka dapat meringankan beberapa beban Central Processing Unit (CPU) yaitu pengeditan, pengendalian, pengalihan, dan penyimpanan data, memproses keperluan terminal bodoh. Terminal bodoh mengandalkan CPU untuk semua manipulasi data, termasuk pengeditan dan pembaharuan.
Daftar Pustaka:
Kendall, Kendall, 2003, Analisis dan Perancangan Sistem Edisi kelima Jilid 2, Jakarta, PT Indeks Kelompok Gramedia
Wednesday, October 23, 2013
Tuesday, October 8, 2013
Tugas ke-5 Matakuliah Perancangan Sistem Informasi
NIM : 112100925
Nama : Joko Gunawan
Semester/Kelas : 5/C3
Jurusan : Teknik Informatika
Jenjang : S1
Matakuliah : Perancangan Sistem Informasi
Soal:
Jawaban nomor 1:
Nielsen and Mack (1994) and Nielsen, Molich, Snyder, and Farrell (2001) have published usability heuristics (or rules of thumb) based on thousands of usability tests of interfaces and, later, tests of ecommerce Web sites. They include visibility of system status, match between the system and the real world, user control and freedom, consistency and standards, error prevention, reconnection rather than recall, flexibility and efficiency of use, aesthetic and minimalist design, help that users recognize, diagnosis and recovery from errors, and help and documentation. Some of these are already familiar to you from the input and output design chapters.
Nielsen dan Mack (1994) dan Nielsen, Molich, Snyder, dan Farrell (2001) telah menerbitkan kegunaan heuristik (aturan baku) berdasarkan ribuan tes kegunaan antarmuka dan kemudian tes mengenai situs dari web e-commerce. Mereka mengisi visibilitas dari status sistem, memabndingkan antara sistem tersebut dengan dunia nyata, kontrol dari pengguna dan kebebasan, konsistensi dan standar-standar, mencegah kesalahan, rekoneksi daripada mengingat, fleksibilitas dan efisiensi dalam hal penggunaan, estetika dan desain minimalis, yang membantu pengguna untuk mengenali, mendiagnosa dan memulihkan kesalahan-kesalahan yang terjadi, dan bantuan dan dokumentasi. Beberapa di antaranya sudah akrab bagi Anda dari pembelajaran bab input dan output desain.
Jawaban nomor 2:
Your goal must be to design interfaces that help users and businesses get the information they need in and out of the system by addressing the following objectives:
Ketika mengevaluasi antarmuka yang Anda pilih, ada beberapa standar yang perlu diingat:
Daftar Pustaka:
Kendall, Kendall, 2003, Analisis dan Perancangan Sistem Edisi kelima Jilid 2, Jakarta, PT Indeks Kelompok Gramedia
Nama : Joko Gunawan
Semester/Kelas : 5/C3
Jurusan : Teknik Informatika
Jenjang : S1
Matakuliah : Perancangan Sistem Informasi
Soal:
- List five of the eleven usability heuristic for judging the usability of computer system and ecommerce website provided by nielsen and others.
- What are 5 objectives for designing user interfaces.
Jawaban nomor 1:
Nielsen and Mack (1994) and Nielsen, Molich, Snyder, and Farrell (2001) have published usability heuristics (or rules of thumb) based on thousands of usability tests of interfaces and, later, tests of ecommerce Web sites. They include visibility of system status, match between the system and the real world, user control and freedom, consistency and standards, error prevention, reconnection rather than recall, flexibility and efficiency of use, aesthetic and minimalist design, help that users recognize, diagnosis and recovery from errors, and help and documentation. Some of these are already familiar to you from the input and output design chapters.
Nielsen dan Mack (1994) dan Nielsen, Molich, Snyder, dan Farrell (2001) telah menerbitkan kegunaan heuristik (aturan baku) berdasarkan ribuan tes kegunaan antarmuka dan kemudian tes mengenai situs dari web e-commerce. Mereka mengisi visibilitas dari status sistem, memabndingkan antara sistem tersebut dengan dunia nyata, kontrol dari pengguna dan kebebasan, konsistensi dan standar-standar, mencegah kesalahan, rekoneksi daripada mengingat, fleksibilitas dan efisiensi dalam hal penggunaan, estetika dan desain minimalis, yang membantu pengguna untuk mengenali, mendiagnosa dan memulihkan kesalahan-kesalahan yang terjadi, dan bantuan dan dokumentasi. Beberapa di antaranya sudah akrab bagi Anda dari pembelajaran bab input dan output desain.
Jawaban nomor 2:
Your goal must be to design interfaces that help users and businesses get the information they need in and out of the system by addressing the following objectives:
- Matching the user interface to the task.
- Making the user interface efficient.
- Providing appropriate feedback to users.
- Generating usable queries.
- Improving the productivity of computer users.
Ketika mengevaluasi antarmuka yang Anda pilih, ada beberapa standar yang perlu diingat:
- Masa pelatihan yang penting bagi pengguna harus singkat.
- Pengguna yang masih baru dalam pelatihan harus dapat memasukkan perintah tanpa memikirkan tentang diri mereka atau tanpa mengacu dalam menu bantuan atau buku manual. Jagalah agar antarmuka tersebut konsisten sepanjang aplikasi-aplikasi tersebut dapat membantu dalam hal ini.
- Antarmuka selayaknya dibuat "tidak asalan" sehingga mengurangi kesalahan-kesalahan dan kesalahan yang telah terjadi tidak terjadi lagi karena rancangan yang buruk.
- Waktu yang diperlukan oleh pengguna dan sistem untuk memperbaiki kesalahan harus singkat.
- Pengguna yang jarang memakai harus mampu mempelajari kembali sistemnya dengan cepat.
Daftar Pustaka:
Kendall, Kendall, 2003, Analisis dan Perancangan Sistem Edisi kelima Jilid 2, Jakarta, PT Indeks Kelompok Gramedia
Tuesday, October 1, 2013
Tugas ke-4 Matakuliah Perancangan Sistem Informasi
NIM : 112100925
Nama : Joko Gunawan
Semester/Kelas : 5/C3
Jurusan : Teknik Informatika
Jenjang : S1
Matakuliah : Perancangan Sistem Informasi
Soal:
Jawaban nomor 1:
Salah satu utama untuk normalisasi adalah mengatur data sedemikian hingga dengan maksud mengurangi data yang berlebihan. Jika Anda tidak memerlukan untuk menyimpan data sama yang lebih dan lebih lagi, Anda dapat menyimpan transaksi jarak yang lebih besar. Organisasi yang demikian membolehkan penganalisis untuk mengurangi jumlah penyimpanan yang diperlukan, kadang-kadang sangat penting jika penyimpanan mahal.
Kita mempelajari dalam bagian akhir bahwa menggunakan data normal kita harus mengembangkan melalui suatu rangkaian langkah-langkah yang meliputi penggabungan, pengurutan, dan ringkasan. Jika kecepatan pertanyaan basisdata (yaitu, menanyakan sebuah pertanyaan dan memerlukan jawaban yang cepat) adalah kritir, maka penting untuk menyimpan data dalam cara yang lain.
Denormalisasi adalah proses mengambil model data logika dan mengubahnya ke dalam suatu model fisik yang efisien untuk tugas-tugas yang sangat sering dibutuhkan. Tugas tersebut meliputi membangkitkan laporan, tetapi dapat berarti juga pertanyaan yang lebih efisien. Pertanyaan yang kompleks seperti proses online analytic processing (OLAP) sebaik data pertambangan dan knowledge data discovery (KDD) dapat juga membuat kegunaan basisdata denormalisasi.
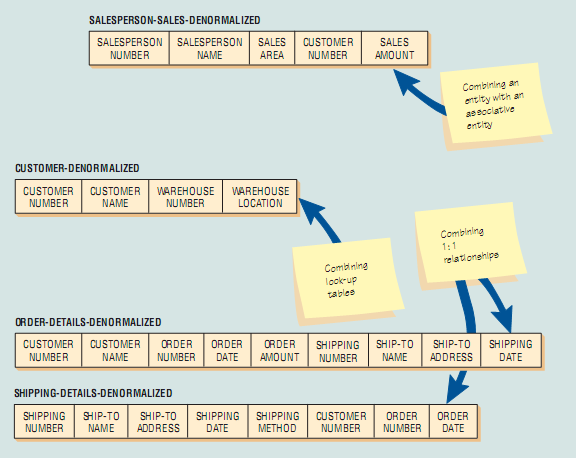
Denormalisasi dapat dikerjakan dengan sejumlah cara berbeda. Gambar dibawah menunjukkan beberapa pendekatan tersebut. Pertama, kita dapat mengambil hubungan banyak ke banyak, seperti sales dan pelanggan yang memberikan asosiatif entitas penjualan. Dengan menggabungkan atribut dari sales dan penjualan kita dapat menghindari satu dari proses gabungan. Hal ini hasilnya jumlah duplikasi data yang dapat dipertimbangkan, tetapi hal itu membantu pertanyaan mengenai pola penjualan untuk lebih efisien.
Alasan untuk denormalisasi adalah menghindari referensi terulang untuk melihat tabel. Akan lebih efisien untuk mengulang informasi yang sama. Sebagai contoh, kota, negara, dan kode pos bahkan informasi ini biasanya disimpan hanya sebagai kode pos. Oleh karena itu, dalam contoh penjualan, pelanggan dan gudang dapat digabungkan.
Akhirnya, kita melihat pada hubungan satu ke satu karena hubungan tersebut mungkin sekali digabungkan untuk alasan yang praktis. Jika kita mempelajari bahwa banyak pertanyaan mengenai pesanan juga menarik perhatian dengan cara bagaimana pesanan dikirimkan, akan membuat pengertian untuk menggabungkan, atau denormalisasi. Oleh karena itu, dalam contoh, beberapa detail dapat muncul dalam kedua detail-pesanan dan detail-pengiriman jika kita menuju denormalisasi.
Jawaban nomor 2:
Gudang data berbeda dari basisdata tradisional. Tujuan gudang data adalah untuk mengatur informasi supaya pertanyaan cepat dan efektif. Sebenarnya, gudang data menyimpan denormalisasi informasi, tetapi untuk menuju satu langkah lebih jauh. Gudang data mengatur data sekitar persoalan. Sangat sering, sebuah gudang data adalah lebih dari satu proses basisdata sehingga informasi tersebut diwakili dalam cara yang sama. Oleh karena itu, informasi yang disimpan dalam gudang data berasal dari sumber yang berbeda, biasanya basisdata yang diset up untuk tujuan berbeda.
Konsep gudang data adalah khas. Perbedaan antara gudang data dan basisdata tradisional meliputi berikut:
Daftar Pustaka:
Kendall, Kendall, 2003, Analisis dan Perancangan Sistem Edisi kelima Jilid 2, Jakarta, PT Indeks Kelompok Gramedia
Nama : Joko Gunawan
Semester/Kelas : 5/C3
Jurusan : Teknik Informatika
Jenjang : S1
Matakuliah : Perancangan Sistem Informasi
Soal:
- Definisikan denormalisasi.
- Jelaskan perbedaan antara basisdata tradisional dan gudang data.
Jawaban nomor 1:
Salah satu utama untuk normalisasi adalah mengatur data sedemikian hingga dengan maksud mengurangi data yang berlebihan. Jika Anda tidak memerlukan untuk menyimpan data sama yang lebih dan lebih lagi, Anda dapat menyimpan transaksi jarak yang lebih besar. Organisasi yang demikian membolehkan penganalisis untuk mengurangi jumlah penyimpanan yang diperlukan, kadang-kadang sangat penting jika penyimpanan mahal.
Kita mempelajari dalam bagian akhir bahwa menggunakan data normal kita harus mengembangkan melalui suatu rangkaian langkah-langkah yang meliputi penggabungan, pengurutan, dan ringkasan. Jika kecepatan pertanyaan basisdata (yaitu, menanyakan sebuah pertanyaan dan memerlukan jawaban yang cepat) adalah kritir, maka penting untuk menyimpan data dalam cara yang lain.
Denormalisasi adalah proses mengambil model data logika dan mengubahnya ke dalam suatu model fisik yang efisien untuk tugas-tugas yang sangat sering dibutuhkan. Tugas tersebut meliputi membangkitkan laporan, tetapi dapat berarti juga pertanyaan yang lebih efisien. Pertanyaan yang kompleks seperti proses online analytic processing (OLAP) sebaik data pertambangan dan knowledge data discovery (KDD) dapat juga membuat kegunaan basisdata denormalisasi.
Denormalisasi dapat dikerjakan dengan sejumlah cara berbeda. Gambar dibawah menunjukkan beberapa pendekatan tersebut. Pertama, kita dapat mengambil hubungan banyak ke banyak, seperti sales dan pelanggan yang memberikan asosiatif entitas penjualan. Dengan menggabungkan atribut dari sales dan penjualan kita dapat menghindari satu dari proses gabungan. Hal ini hasilnya jumlah duplikasi data yang dapat dipertimbangkan, tetapi hal itu membantu pertanyaan mengenai pola penjualan untuk lebih efisien.
 |
| Perhitungan memberikan subtotal, total, dan hasil hitungan lainnya |
 |
| Perhitungan memberikan subtotal, total, dan hasil hitungan lainnya |
Alasan untuk denormalisasi adalah menghindari referensi terulang untuk melihat tabel. Akan lebih efisien untuk mengulang informasi yang sama. Sebagai contoh, kota, negara, dan kode pos bahkan informasi ini biasanya disimpan hanya sebagai kode pos. Oleh karena itu, dalam contoh penjualan, pelanggan dan gudang dapat digabungkan.
Akhirnya, kita melihat pada hubungan satu ke satu karena hubungan tersebut mungkin sekali digabungkan untuk alasan yang praktis. Jika kita mempelajari bahwa banyak pertanyaan mengenai pesanan juga menarik perhatian dengan cara bagaimana pesanan dikirimkan, akan membuat pengertian untuk menggabungkan, atau denormalisasi. Oleh karena itu, dalam contoh, beberapa detail dapat muncul dalam kedua detail-pesanan dan detail-pengiriman jika kita menuju denormalisasi.
Jawaban nomor 2:
Gudang data berbeda dari basisdata tradisional. Tujuan gudang data adalah untuk mengatur informasi supaya pertanyaan cepat dan efektif. Sebenarnya, gudang data menyimpan denormalisasi informasi, tetapi untuk menuju satu langkah lebih jauh. Gudang data mengatur data sekitar persoalan. Sangat sering, sebuah gudang data adalah lebih dari satu proses basisdata sehingga informasi tersebut diwakili dalam cara yang sama. Oleh karena itu, informasi yang disimpan dalam gudang data berasal dari sumber yang berbeda, biasanya basisdata yang diset up untuk tujuan berbeda.
Konsep gudang data adalah khas. Perbedaan antara gudang data dan basisdata tradisional meliputi berikut:
- Dalam gudang data, data diatur di sekitar permasalahan utama daripada transaksi individual.
- Data dalama sebuah gudang data disimpan secara khusus sebagai data ringkasan daripada dalam detail, data asli ditemukan dalam suatu basisdata penyesuaian transaksi.
- Data dalam gudang data mencakup frame waktu lebih lama daripada data dalam basisdata penyesuaian-transaksi tradisional karena pertanyaan biasanya mengenai membuat keputusan yang lebih lama daripada detail transaksi harian.
- Sebagian besar gudang data diatur untuk pertanyaan yang cepat, di mana basisdata yang lebih tradisional dinormalisasikan dan di susun dalam suatu cara demikian dengan maksud memberikan penyimpan informasi yang efisien.
- Gudang data biasanya dioptimalisasikan untuk menjawab pertanyaan kompleks, yang diketahui sebagai OLAP, dari manajer dan pennganalisis daripada sederhana, menanyakan pertanyaan berulang-ulang.
- Gudang data membolehkan akses secara mudah via perangkat lunak data pertambangan (disebut siftware) yang menyelidiki pola dan dapat mengidentifikasi hubungan yang tidak dibayangkan oleh orang yang membuat keputusan.
- Gudang data meliputi tidak hanya satu tetapi multipel basisdata yang telah diproses sehingga data gudang tersebut ditentukan secara sama. Basisdata tersebut dipandang sebagai data "bersih".
- Gudang data biasanya meliputi data dari sumber di luar (seperti laporan industri, the company's security and exchange commision filing, atau informasi lengkap mengenai produk saingan) dan juga data yang dibangkitkan untuk kegunaan internal.
Daftar Pustaka:
Kendall, Kendall, 2003, Analisis dan Perancangan Sistem Edisi kelima Jilid 2, Jakarta, PT Indeks Kelompok Gramedia